

정의
개념을 알기위해 선형회귀분석과 Logistic 회귀분석의 차이점을 알아보자
선형회귀분석은 종속변수가 어떤 값이라도 가질 수 있지만 연속형 숫자여야만 하고 (int값)
Logistic 회귀분석은 종속변수에 제한값이 있지만 (가질 수 없는 값이 존재) 종속변수가 범주형 자료여도 적용이 가능하다.
범주형 자료와 연속형 자료의 차이점은 아래의 블로그를 참조
[통계] 자료의 형태 - 범주형 자료, 수치형 자료, 척도
통계 분석을 시작하기 전에 자료의 형태를 파악하는 것은 필수적입니다. 수집된 자료는 크게 범주형 자료와...
blog.naver.com
위를 표로 설명하면 아래와 같다.

Logistic 회귀분석의 종류
종류에는 여러가지가 있지만 그 중 대표적인 Boosting Logistic Regression과 Logistic Model Trees, Penalized Logistic Regression, Regularized Logistic Regression이 있는데 쉽게 풀이하자면 아래의 설명과 같다.
Boosting Logistic Regression은 약한 모델들을 겹겹이 더해가며 강하게 만드는 방식
Logistic Model Trees는 Logistic과 Tree 알고리즘의 개념을 합친 알고리즘.
Penalized Logistic Regression
Regularized Logistic Regression
나중에 train()에서 method를 각각 아래와 같이 지정하여 사용 가능하다.
Boosting Logistic Regression = "LogitBoost"
Logistic Model Trees = "LMT"
Penalized Logistic Regression = "plr"
Regularized Logistic Regression = "regLogistic"
Boosting Logistic Regression
약한 분류기이지만 분류기를 추가하여 정확도를 높이는 알고리즘 방식이다.
적은 x 피처를 가지고 정확도를 추출하는 방식이라 낮은 정확도를 가지고 있지만 다른 피처의 데이터를 점점 추가하여 정확도를 높인다.
따라서 작은 모델 모형으로 시작하지만 모형들을 합쳐 모델 모형을 개선해나가는 방식의 알고리즘이라고 볼 수 있다.
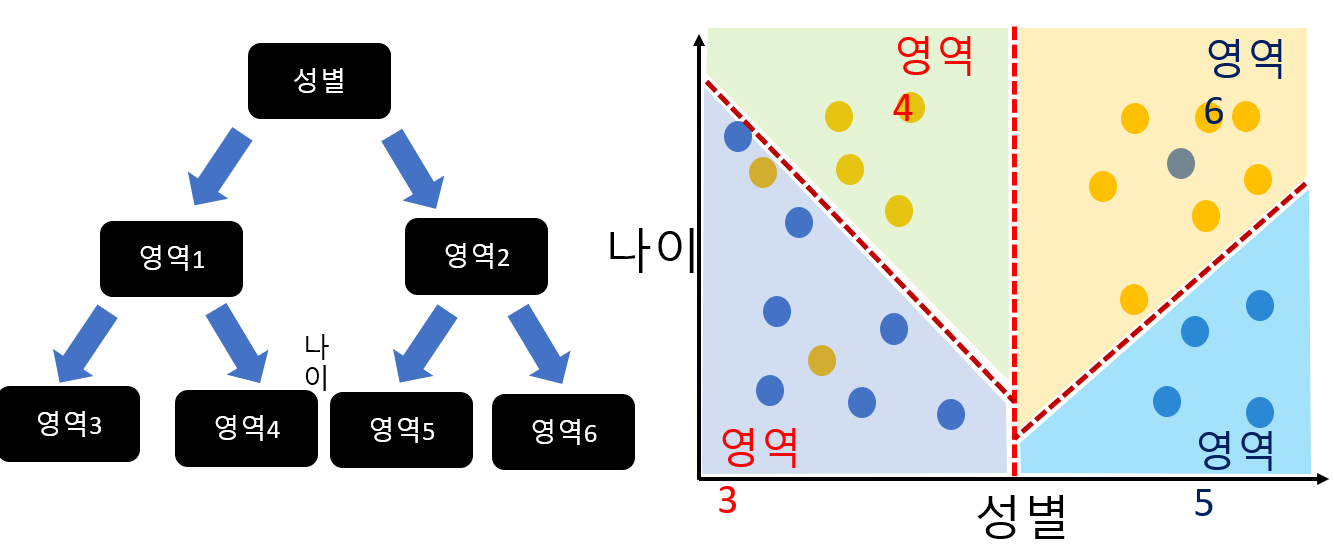
Logistic Model Trees
Tree알고리즘과 Logistic알고리즘을 합쳐논 것.
일단 성별과 나이의 군집도를 확인한 후에 그 영역을 tree가 나누어주고 영역 안에서 Logistic알고리즘을 수행함으로써 적합한 데이터를 분석하는 방식
Penalized Logistic Regression
Penalized. 즉 로지스틱 회귀분석에 제한성을 두는 방식인데 이 제한을 B베타에게 주게 된다.
베타의 값에 제한을 두게 됨으로써 B^2은 < T보다 작게되고 이 제한을 두게됨으로써 베타의 영역 넓이가 제한된다.
*L2 정규화
베타에 제한을 두는 이유는 모델의 복잡성을 최소화시키면서 이로 인한 overfitting을 방지할 수 있기 때문이다.
L2 정규화 = Ridge 라고 부름

Regularized Logistic Regression
penalized 로지스틱을 사용할 때 데이터를 L2정규화를 한다고 하면 Regulized 로지스틱 회귀분석은 L1정규화를 시행한다.
L2정규화는 베타의 합에 제곱을 하지만 L1정규화는 베타의 합에 절대값을 쓰는 차이점이 있다.
L1정규화 = Lasso라고 부름

R로 Boosting Logistic Regression 사용법
knn 알고리즘 방식과 실행방법은 동일하다.
데이터를 받고 원본데이터 보존
#데이터 확인
raw_data <- read.csv('Data/heart.csv')
str(raw_data)
#원본데이터 보존
data <- raw_data
데이터 타입을 str()로 확인하고 범주형 데이터, 표준화 변경
as.factor 작업을 할 때 아래의 lapply를 사용하여 한번에 변경
#target 데이터 범주형으로 변환
data$target <- as.factor(data$target)
#데이터 set화. 유일한 값 추출
unique(data$target)
#나머지 데이터도 한꺼번에 범주화
#lapply활용
factor_var <- c('sex','cp','fbs','restecg',
'exang','ca','thal')
data[,factor_var] <- lapply(data[,factor_var], factor)
str(data)
#연속형 독립변수 표준화
data$age <- scale(data$age)
data$trestbps <- scale(data$trestbps)
data$chol <- scale(data$chol)
data$thalach <- scale(data$thalach)
data$oldpeak <- scale(data$oldpeak)
data$slope <- scale(data$slope)
학습용, 실습용 데이터 분리
#데이터 나누기
set.seed(1234)
datatotal <- sort(sample(nrow(data), nrow(data)*0.7))
train <- data[datatotal,]
test <- dta[-datatotal,]
train_x <- train[,1:12]
test_x <- test[,13]
train_y <- train[, 1:12]
test_y <- test[, 13]
분리한 데이터 모델링 실행 후 머신러닝 실행
이 때 현재 방식은 Boosting Logistic Regression이므로 method방식에 LogitBoost를 대입하여 사용
#데이터 모델링
ctrl <- trainControl(method = "repeatedcv",
repeats = 5
)
logitFit <- train(target ~.,
data=train,
method='LogitBoost',
trControl=ctrl,
metric='Accuracy'
)
도출된 결과물
알고리즘 방식이 Boosting Losgistic Regression이므로 현재 31번 모델들을 더해야 최적의 값을 찾을 수 있다는 것을 확인할 수 있다.

받은 데이터 시각화
plot(logitFit)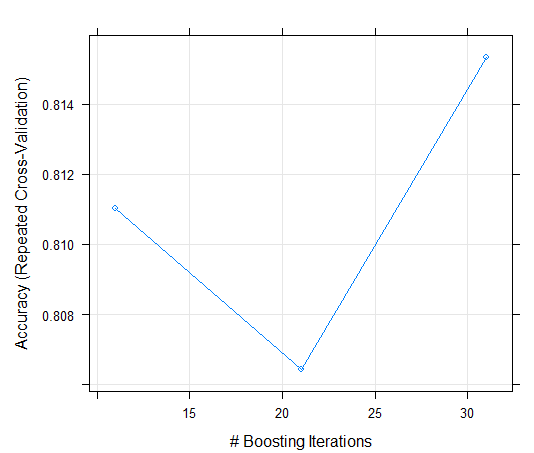
만들어진 모델로 실제 데이터로 테스트
#만들어진 모델로 실제 데이터 테스트
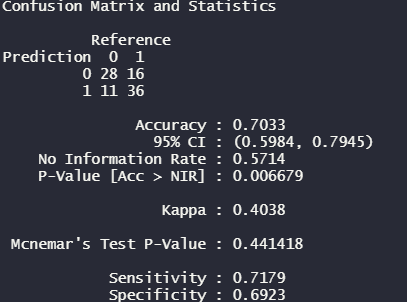
pred_test <- predict(logitFit, newdata = test)
confusionMatrix(pred_test, test$target)아래 결과물의 최종 예측치는 70%인 것을 확인할 수 있다. train데이터에서 확인한 80%보다 10% 줄은 모습
모델의 변수 중요성 파악 및 시각화
#머신러닝에 주어진 변수 중요성 파악 및 시각화
var_importance <- varImp(logitFit, scale = F)
var_importance
plot(var_importance)아래의 시각화를 참고하여 thalach라는 변수가 결과물 도출에 제일 상관관계가 크다는 것을 참고할 수 있다.

'R - 통계 언어' 카테고리의 다른 글
| R로 하는 머신러닝 Decision Tree와 Random Forest 개념, 사용 예시 설명 및 결과 해석 (0) | 2022.06.04 |
|---|---|
| R을 사용하여 가설검정하기 - Z 검정 (0) | 2022.06.02 |
| R을 사용하여 가설검정하기 - 대응표본 t 검정 (0) | 2022.06.02 |
| R을 사용하여 가설검정하기 - T 테스트 (0) | 2022.06.01 |
| R 데이터 내 이상치, 극단치 제거하는 법 (1) | 2022.06.01 |