

728x90
반응형
TreeSet
이진 탐색 트리로 구현되어 있고 범위탐색과 정렬에 유리함
이진 트리는 각각의 노드가 최대 0~2개의 노드를 가질 수 있음
각각의 노드 중 작은 값은 부모의 왼쪽, 큰 값은 부모의 오른쪽에 저장된다.

이 때문에 값을 추가하거나 삭제할 때 비교시간이 더 걸리게 된다.
- 값이 작으면 왼쪽, 크면 오른쪽에 저장되기 때문에 새로운 값이 들어가거나 기존의 값이 없어지게되면 값을 새롭게 비교해야되므로 시간적으로 효율이 떨어짐
TreeSet의 저장과정
다른 Set클래스들과 동일하게 add()를 사용
수정용
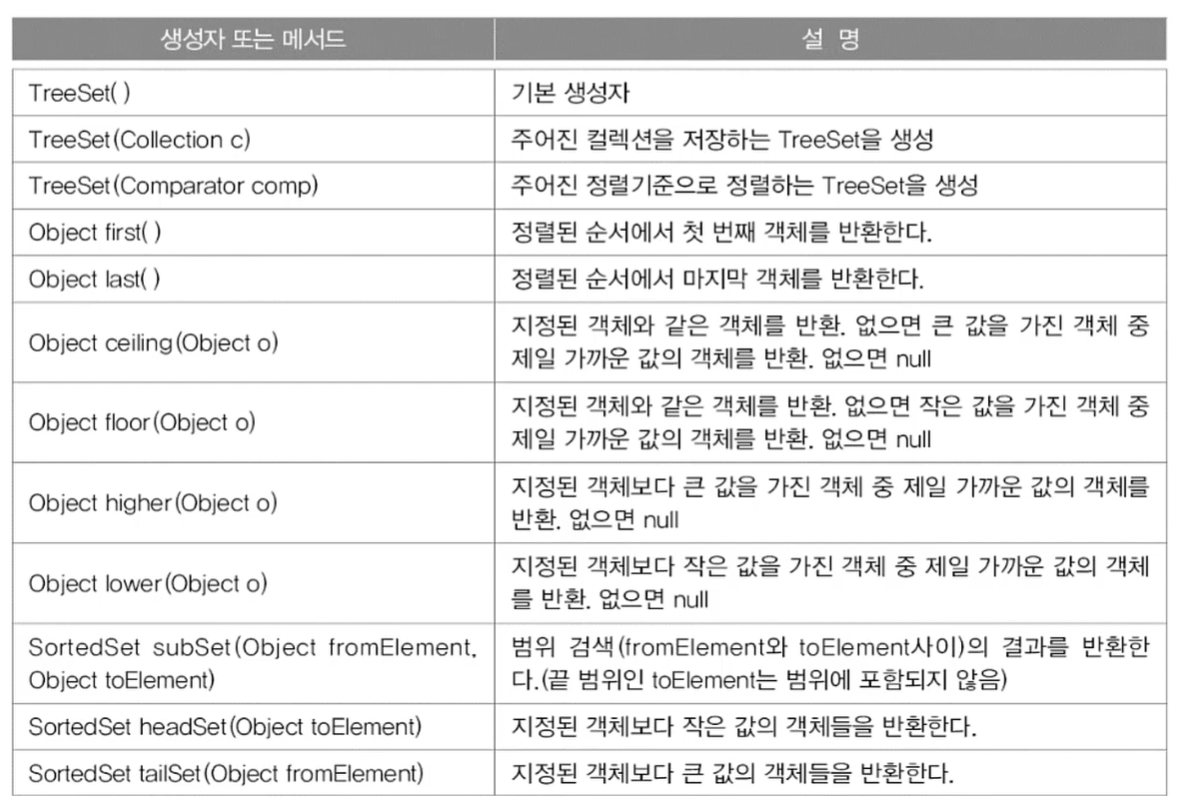
TreeSet의 메서드
본
HashSet과 달리 TreeSet은 정렬이 필요없다.
출력문: [4, 5, 7, 9]
Set set = new TreeSet();
set.add(5);
set.add(4);
set.add(7);
set.add(9);
System.out.println(set);
// [4, 5, 7, 9]
TreeSet 메서드 활용
TreeSet의 Subset 메서드 활용
출력문:
[apple, banana, cat, double, erect, fancy]
[banana, cat]
TreeSet set = new TreeSet();
String[] add = {"banana","double","cat","apple","fancy","erect"};
for(String list : add) {
set.add(list);
}
System.out.println(set);
System.out.println(set.subSet("b", "d"));
// subset 메서드는 TreeSet의 고유의 메서드이므로 형변환하지않고 TreeSet을 선언하여
// subSet from ~ to (b의 스펠링부터 d까지)를 사용하여 banana와 cat을 출력
TreeSet의 headSet & tailSet메서드 활용
출력문:
50보다 작은 객체만 출력: [30, 40]
50보다 크거나 같은 객체만 출력: [50, 60, 70, 90]
TreeSet set2 = new TreeSet();
int[] i = {50,40,30,50,60,70,90};
for(int list : i) {
set2.add(list);
}
System.out.println(set2);
System.out.println("50보다 작은 객체만 출력: " + set2.headSet(50));
System.out.println("50보다 크거나 같은 객체만 출력: " + set2.tailSet(50));
Integer값 말고 String값도 대입이 가능하다.
예시:
System.out.println("c보다 작은 객체만 출력: " + set.headSet("c"));
// c보다 작은 객체만 출력: [apple, banana]
728x90
반응형
'Java > 자바의정석 기초편' 카테고리의 다른 글
| 자바의 정석 11장 (30일차) - Collections 클래스 (0) | 2022.02.21 |
|---|---|
| 자바의 정석 11장 (30일차) - HashMap (0) | 2022.02.21 |
| 자바의 정석 11장 (29일차) - HashSet (0) | 2022.02.20 |
| 자바의 정석 11장 (29일차) - Arrays 메서드 (0) | 2022.02.20 |
| 자바의 정석 11장 (29일차) - Iterator (0) | 2022.02.20 |